Achievement: Researchers at Oak Ridge National Laboratory developed a new parallel performance portable algorithm for solving the Euclidean minimum spanning tree problem (EMST), capable of processing tens of millions of data points a second. The problem frequently arises in data clustering, astronomy, molecular dynamics, network planning, and many other applications. With an increase in problem sizes to hundreds of millions of data points, there is a growing demand for high-performance parallel EMST algorithms that can take advantage of multicore and GPU computing architectures.
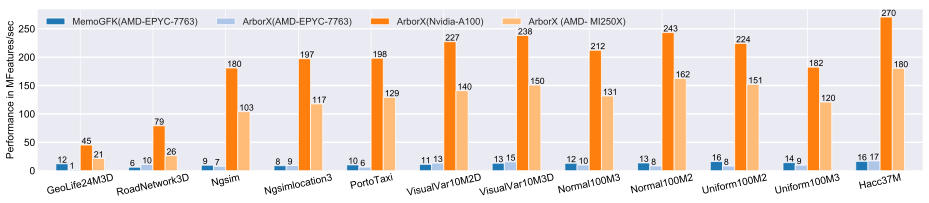
In response to this demand, researchers at Oak Ridge National Laboratory (ORNL) recently developed a new algorithm for the EMST problem that is 24 times faster than state-of-the-art multithreaded implementations and scales well across the latest serial, multicore, and GPU architectures. The new algorithm was implemented in the open-source ArborX library and can process 90 million of 3D data a second using a single Nvidia A100 (GPU on NERSC’s Perlmutter), and 60 million using a single AMD MI250X (single GCD) (GPU on OLCF’s Frontier), respectively.
Significance and Impact: This work is motivated by an astronomy application that requires fast computational algorithms to perform in-situ analysis of the cosmological data. The previous multithreaded algorithms were unable to make full use of the available GPUs and were therefore too slow for in-situ analysis. The newly developed algorithms represent a significant speedup over the previous implementations. The algorithm lets researchers process 37 million 3D cosmological datasets in under 0.5 seconds - 17 times faster than the best-known multithreaded implementation on the latest AMD EPYC 7763 which takes 8.5 seconds to do it.
In addition to immediate impact, the new algorithm improves productivity for researchers in machine learning and scientific data analysis communities. Furthermore, it closes the gap to scaling a popular HDBSCAN* clustering algorithm, where computing EMST is one of the steps.
Research Details
- The new algorithm is based on Borůvka’s algorithm and uses a single tree to perform the nearest-neighbor queries.
- A bounding volume hierarchy (BVH) is used as the tree structure as it is very efficient for unstructured low-dimensional data on GPU.
- Several optimizations of the tree traversal were used to accelerate the algorithm, including pruning the number of distance calculations by bypassing subtrees with leaves in the same Borůvka component.
- In the implementation, ArborX, a performance portable geometric search library using Kokkos framework, was used.
- The algorithm was studied on both CPU and multiple GPU architectures (Nvidia A100, AMD MI250X).
Facility: Oak Ridge Leadership Computing Facility
Sponsor/Funding: DOE ASCR
PI and affiliation: Andrey Prokopenko, Scalable Algorithms and Coupled Physics Group, Computational Science and Engineering Division, ORNL
Team: Piyush Sao, Damien Lebrun-Grandie (ORNL)
Citation and DOI: DOI: 10.1145/3545008.3546185
Summary: ORNL researchers provided the first performance portable algorithm and implementation for the EMST problem.
Researchers evaluated the proposed algorithm on various 2D and 3D datasets, compared it with state-of-the-art open-source CPU implementations, and demonstrated speedup rates of 4-24× over the fastest multithreaded implementation. The researchers also provided results on a variety of hardware: AMD EPYC 7763, Nvidia A100, and AMD MI250X.
Researchers showed that their proposed algorithm gracefully handles certain non-Euclidean distances. Specifically, their algorithm is efficient when using a mutual reachability distance, a variant of Euclidean distance used in a popular clustering algorithm, HDBSCAN* (McInnes et al. 2017).
Researchers provided a comprehensive set of experiments on three architectures to establish empirical evidence for several properties of their algorithm and implementation including performance portability, asymptotic linear cost growth with problem size and lower threshold problem size to achieve performance saturation relative to CPU.

